Ошибка аппроксимации больше 10. Оценка с помощью F-критерия Фишера статистической надежности результатов регрессионного моделирования. Показатели корреляции и детерминации
Ум заключается не только в знании, но и в умении прилагать знание на деле. (Аристотель)
Доверительные интервалы
Общий обзор
Взяв выборку из популяции, мы получим точечную оценку интересующего нас параметра и вычислим стандартную ошибку для того, чтобы указать точность оценки.
Однако, для большинства случаев стандартная ошибка как такова не приемлема. Гораздо полезнее объединить эту меру точности с интервальной оценкой для параметра популяции.
Это можно сделать, используя знания о теоретическом распределении вероятности выборочной статистики (параметра) для того, чтобы вычислить доверительный интервал (CI - Confidence Interval, ДИ - Доверительный интервал) для параметра.
Вообще, доверительный интервал расширяет оценки в обе стороны некоторой величиной, кратной стандартной ошибке (данного параметра); два значения (доверительные границы), определяющие интервал, обычно отделяют запятой и заключают в скобки.
Доверительный интервал для среднего
Использование нормального распределения
Выборочное среднее имеет нормальное распределение, если объем выборки большой, поэтому можно применить знания о нормальном распределении при рассмотрении выборочного среднего.
В частности, 95% распределения выборочных средних находится в пределах 1,96 стандартных отклонений (SD) среднего популяции.
Когда у нас есть только одна выборка, мы называем это стандартной ошибкой среднего (SEM) и вычисляем 95% доверительного интервала для среднего следующим образом:
Если повторить этот эксперимент несколько раз, то интервал будет содержать истинное среднее популяции в 95% случаев.
Обычно это доверительный интервал как, например, интервал значений, в пределах которого с доверительной вероятностью 95% находится истинное среднее популяции (генеральное среднее).
Хотя это не вполне строго (среднее в популяции есть фиксированное значение и поэтому не может иметь вероятность, отнесённую к нему) таким образом интерпретировать доверительный интервал, но концептуально это удобнее для понимания.
Использование t- распределения
Можно использовать нормальное распределение, если знать значение дисперсии в популяции. Кроме того, когда объем выборки небольшой, выборочное среднее отвечает нормальному распределению, если данные, лежащие в основе популяции, распределены нормально.
Если данные, лежащие в основе популяции, распределены ненормально и/или неизвестна генеральная дисперсия (дисперсия в популяции), выборочное среднее подчиняется t-распределению Стьюдента
.
Вычисляем 95% доверительный интервал для генерального среднего в популяции следующим образом:
Где - процентная точка (процентиль) t- распределения Стьюдента с (n-1) степенями свободы, которая даёт двухстороннюю вероятность 0,05.
Вообще, она обеспечивает более широкий интервал, чем при использовании нормального распределения, поскольку учитывает дополнительную неопределенность, которую вводят, оценивая стандартное отклонение популяции и/или из-за небольшого объёма выборки.
Когда объём выборки большой (порядка 100 и более), разница между двумя распределениями (t-Стьюдента и нормальным) незначительна. Тем не менее всегда используют t- распределение при вычислении доверительных интервалов, даже если объем выборки большой.
Обычно указывают 95% ДИ. Можно вычислить другие доверительные интервалы, например 99% ДИ для среднего.
Вместо произведения стандартной ошибки и табличного значения t- распределения, которое соответствует двусторонней вероятности 0,05, умножают её (стандартную ошибку) на значение, которое соответствует двусторонней вероятности 0,01. Это более широкий доверительный интервал, чем в случае 95%, поскольку он отражает увеличенное доверие к тому, что интервал действительно включает среднее популяции.
Доверительный интервал для пропорции
Выборочное распределение пропорций имеет биномиальное распределение. Однако если объём выборки n
разумно большой, тогда выборочное распределение пропорции приблизительно нормально со средним .
Оцениваем выборочным отношением p=r/n (где r - количество индивидуумов в выборке с интересующими нас характерными особенностями), и стандартная ошибка оценивается:
95% доверительный интервал для пропорции оценивается:

Если объём выборки небольшой (обычно когда np
или n(1-p)
меньше 5
), тогда необходимо использовать биномиальное распределение для того, чтобы вычислить точные доверительные интервалы.
Заметьте, что если p выражается в процентах, то (1-p) заменяют на (100-p) .
Интерпретация доверительных интервалов
При интерпретации доверительного интервала нас интересуют следующие вопросы:
Насколько широк доверительный интервал?
Широкий доверительный интервал указывает на то, что оценка неточна; узкий указывает на точную оценку.
Ширина доверительного интервала зависит от размера стандартной ошибки, которая, в свою очередь, зависит от объёма выборки и при рассмотрении числовой переменной от изменчивости данных дают более широкие доверительные интервалы, чем исследования многочисленного набора данных немногих переменных.
Включает ли ДИ какие-либо значения, представляющие особенный интерес?
Можно проверить, ложится ли вероятное значение для параметра популяции в пределы доверительного интервала. Если да, то результаты согласуются с этим вероятным значением. Если нет, тогда маловероятно (для 95% доверительного интервала шанс почти 5%), что параметр имеет это значение.
Пусть у нас имеется большое количество предметов, с нормальным распределением некоторых характеристик (например, полный склад однотипных овощей, размер и вес которых варьируется). Вы хотите знать средние характеристики всей партии товара, но у Вас нет ни времени, ни желания измерять и взвешивать каждый овощ. Вы понимаете, что в этом нет необходимости. Но сколько штук надо было бы взять на выборочную проверку?
Прежде, чем дать несколько полезных для этой ситуации формул напомним некоторые обозначения.
Во-первых, если бы мы все-таки промерили весь склад овощей (эт о множество элементов называется генеральной совокупностью), то мы узнали бы со всей доступной нам точностью среднее значение веса всей партии. Назовем это среднее значение Х ср.г ен . - генеральным средним. Мы уже знаем, что определяется полностью, если известно его среднее значение и отклонение s . Правда, пока мы ни Х ср.ген., ни s генеральной совокупности не знаем. Мы можем только взять некоторую выборку, замерить нужные нам значения и посчитать для этой выборки как среднее значение Х ср.в ыб., так и среднее квадратическое отклонение S выб.
Известно, что если наша выборочная проверка содержит большое количество элементов (обычно n больше 30), и они взяты действительно случайным образом , то s генеральной совокупности почти не будет отличаться от S выб ..
Кроме того, для случая нормального распределения мы можем пользоваться следующими формулами:
С вероятностью 95%
С вероятностью 99%
![]()
В общем виде c вероятностью Р
(t)
Связь значения t со значением вероятности Р
(t), с
которой мы хотим знать доверительный интервал, можно взять из следующей таблицы:
Таким образом, мы определили, в каком диапазоне находится среднее значение
для генеральной совокупности (с данной вероятностью).
Если у нас нет достаточно большой выборки, мы не можем утверждать, что генеральная совокупность имеет s = S выб. Кроме того, в этом случае проблематична близость выборки к нормальному распределению. В этом случае также пользуются S выб вместо s в формуле:

но значение t для фиксированной вероятности Р
(t)
будет зависеть от количества элементов в выборке n. Чем больше n, тем ближе
будет полученный доверительный интервал к значению, даваемому формулой (1).
Значения t в этом случае берутся из другой таблицы (t-критерий Стьюдента),
которую мы приводим ниже:
Значения t-критерия Стьюдента для
вероятности 0,95 и 0,99

Пример 3.
Из
работников фирмы случайным образом отобрано 30 человек. По выборке оказалось,
что средняя зарплата (в месяц) составляет 30 тыс. рублей при среднем
квадратическом отклонении 5 тыс. рублей. С вероятностью 0,99 определить
среднюю зарплату в фирме.
Решение: По условию имеем n = 30, Х ср. =30000, S=5000, Р = 0,99. Для нахождения доверительного интервала воспользуемся формулой, соответствующей критерию Стьюдента. По таблице для n = 30 и Р = 0,99 находим t=2,756, следовательно,
т.е. искомый доверительный
интервал 27484 < Х ср.ген
< 32516.
Итак, вероятностью 0,99 можно утверждать, что интервал (27484; 32516) содержит внутри себя среднюю зарплату в фирме.
Мы надеемся, что Вы будете пользоваться этим методом, при этом не обязательно, чтобы при Вас каждый раз была таблица. Подсчеты можно проводить в Excel автоматически. Находясь в файле Excel, нажмите в верхнем меню кнопку fx. Затем, выберите среди функций тип "статистические", и из предложенного перечня в окошке - СТЬЮДРАСПОБР. Затем, по подсказке, поставив курсор в поле "вероятность" наберите значение обратной вероятности (т.е. в нашем случае вместо вероятности 0,95 надо набирать вероятность 0,05). Видимо, электронная таблица составлена так, что результат отвечает на вопрос, с какой вероятностью мы можем ошибиться. Аналогично в поле "степень свободы" введите значение (n-1) для своей выборки.
Доверительный интервал для математического ожидания - это такой вычисленный по данным интервал, который с известной вероятностью содержит математическое ожидание генеральной совокупности. Естественной оценкой для математического ожидания является среднее арифметическое её наблюденных значений. Поэтому далее в течение урока мы будем пользоваться терминами "среднее", "среднее значение". В задачах рассчёта доверительного интервала чаще всего требуется ответ типа "Доверительный интервал среднего числа [величина в конкретной задаче] находится от [меньшее значение] до [большее значение]". С помощью доверительного интервала можно оценивать не только средние значения, но и удельный вес того или иного признака генеральной совокупности. Средние значения, дисперсия, стандартное отклонение и погрешность, через которые мы будем приходить к новым определениям и формулам, разобраны на уроке Характеристики выборки и генеральной совокупности .
Точечная и интервальная оценки среднего значения
Если среднее значение генеральной совокупности оценивается числом (точкой), то за оценку неизвестной средней величины генеральной совокупности принимается конкретное среднее, которое рассчитано по выборке наблюдений. В таком случае значение среднего выборки - случайной величины - не совпадает со средним значением генеральной совокупности. Поэтому, указывая среднее значение выборки, одновременно нужно указывать и ошибку выборки. В качестве меры ошибки выборки используется стандартная ошибка , которая выражена в тех же единицах измерения, что и среднее. Поэтому часто используется следующая запись: .
Если оценку среднего требуется связать с определённой вероятностью, то интересующий параметр генеральной совокупности нужно оценивать не одним числом, а интервалом. Доверительным интервалом называют интервал, в котором с определённой вероятностью P находится значение оцениваемого показателя генеральной совокупности. Доверительный интервал, в котором с вероятностью P = 1 - α находится случайная величина , рассчитывается следующим образом:
![]() ,
,
α = 1 - P , которое можно найти в приложении к практически любой книге по статистике.
На практике среднее значение генеральной совокупности и дисперсия не известны, поэтому дисперсия генеральной совокупности заменяется дисперсией выборки , а среднее генеральной совокупности - средним значением выборки . Таким образом, доверительный интервал в большинстве случаев рассчитывается так:
![]() .
.
Формулу доверительного интервала можно использовать для оценки среднего генеральной совокупности, если
- известно стандартное отклонение генеральной совокупности;
- или стандартное отклонение генеральной совокупности не известно, но объём выборки - больше 30.
Среднее значение выборки
является несмещённой оценкой среднего генеральной совокупности .
В свою очередь, дисперсия выборки  не является несмещённой оценкой дисперсии генеральной совокупности .
Для получения несмещённой оценки дисперсии генеральной совокупности в формуле дисперсии выборки объём
выборки n
следует заменить на n
-1.
не является несмещённой оценкой дисперсии генеральной совокупности .
Для получения несмещённой оценки дисперсии генеральной совокупности в формуле дисперсии выборки объём
выборки n
следует заменить на n
-1.
Пример 1. Собрана информация из 100 случайно выбранных кафе в некотором городе о том, что среднее число работников в них составляет 10,5 со стандартным отклонением 4,6. Определить доверительный интервал 95% числа работников кафе.
где - критическое значение стандартного нормального распределения для уровня значимости α = 0,05 .
Таким образом, доверительный интервал 95% среднего числа работников кафе составил от 9,6 до 11,4.
Пример 2. Для случайной выборки из генеральной совокупности из 64 наблюдений вычислены следующие суммарные величины:
сумма значений в наблюдениях ,
сумма квадратов отклонения значений от среднего ![]() .
.
Вычислить доверительный интервал 95 % для математического ожидания.
вычислим стандартное отклонение:
 ,
,
вычислим среднее значение:
![]() .
.
Подставляем значения в выражение для доверительного интервала:
где - критическое значение стандартного нормального распределения для уровня значимости α = 0,05 .
Получаем:
Таким образом, доверительный интервал 95% для математического ожидания данной выборки составил от 7,484 до 11,266.
Пример 3. Для случайной выборки из генеральной совокупности из 100 наблюдений вычислено среднее значение 15,2 и стандартное отклонение 3,2. Вычислить доверительный интервал 95 % для математического ожидания, затем доверительный интервал 99 %. Если мощность выборки и её вариация остаются неизменными, а увеличивается доверительный коэффициент, то доверительный интервал сузится или расширится?
Подставляем данные значения в выражение для доверительного интервала:
где - критическое значение стандартного нормального распределения для уровня значимости α = 0,05 .
Получаем:
![]() .
.
Таким образом, доверительный интервал 95% для среднего данной выборки составил от 14,57 до 15,82.
Вновь подставляем данные значения в выражение для доверительного интервала:
где - критическое значение стандартного нормального распределения для уровня значимости α = 0,01 .
Получаем:
![]() .
.
Таким образом, доверительный интервал 99% для среднего данной выборки составил от 14,37 до 16,02.
Как видим, при увеличении доверительного коэффициента увеличивается также критическое значение стандартного нормального распределения, а, следовательно, начальная и конечная точки интервала расположены дальше от среднего, и, таким образом, доверительный интервал для математического ожидания увеличивается.
Точечная и интервальная оценки удельного веса
Удельный вес некоторого признака выборки можно интерпретировать как точечную оценку удельного веса p этого же признака в генеральной совокупности. Если же эту величину нужно связать с вероятностью, то следует рассчитать доверительный интервал удельного веса p признака в генеральной совокупности с вероятностью P = 1 - α :
 .
.
Пример 4. В некотором городе два кандидата A и B претендуют на пост мэра. Случайным образом были опрошены 200 жителей города, из которых 46% ответили, что будут голосовать за кандидата A , 26% - за кандидата B и 28% не знают, за кого будут голосовать. Определить доверительный интервал 95% для удельного веса жителей города, поддерживающих кандидата A .
Цель – научить студентов алгоритмам вычисления доверительных интервалов статистических параметров.
При статистической обработке данных вычисленные средняя арифметическая, коэффициент вариации, коэффициент корреляции, критерии различия и другие точечные статистики должны получить количественные границы доверия, которые обозначают возможные колебания показателя в меньшую и большую стороны в пределах доверительного интервала.
Пример
3.1
.
Распределение
кальция в сыворотке крови обезьян, как
было установлено ранее, характеризуется
следующими выборочными показателями:
=
11,94 мг%; =
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней (
=
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней ( )
при доверительной вероятностиP
= 0,95.
)
при доверительной вероятностиP
= 0,95.
Генеральная средняя находится с определенной вероятностью в интервале:
 ,
где
,
где
 –
выборочная средняя арифметическая;t
– критерий Стьюдента;
–
выборочная средняя арифметическая;t
– критерий Стьюдента;
 –
ошибка средней арифметической.
–
ошибка средней арифметической.
По
таблице «Значения критерия Стьюдента»
находим значение
 при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
или
11,69
 12,19
12,19
Таким образом, с вероятностью 95%, можно утверждать, что генеральная средняя данного нормального распределения находится между 11,69 и 12,19 мг%.
Пример
3.2
. Определите
границы 95%-ного доверительного интервала
для генеральной дисперсии ( )
распределения кальция в крови обезьян,
если известно, что
)
распределения кальция в крови обезьян,
если известно, что =
1,60, приn
= 100.
=
1,60, приn
= 100.
Для решения задачи можно воспользоваться следующей формулой:
Где
 –
статистическая ошибка дисперсии.
–
статистическая ошибка дисперсии.
Находим
ошибку выборочной дисперсии по формуле:
 .
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
.
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
Воспользуемся формулой и получим:
или
1,38
 1,82
1,82
Более
точно доверительный интервал генеральной
дисперсии можно построить с применением
 (хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия
(хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле
для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле ,
для верхней –
,
для верхней – .
Например, для доверительного уровня
.
Например, для доверительного уровня =
0,99
=
0,99 = 0,010,
= 0,010, =
0,990. Соответственно по таблице распределения
критических значений
=
0,990. Соответственно по таблице распределения
критических значений ,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
 и
и .
Получаем
.
Получаем равно 135,80, а
равно 135,80, а равно70,06.
равно70,06.
Чтобы
найти доверительные границы генеральной
дисперсии с помощью
 воспользуемся
формулами: для нижней границы
воспользуемся
формулами: для нижней границы ,
для верхней границы
,
для верхней границы .
Подставим данные задачи найденные
значения
.
Подставим данные задачи найденные
значения в
формулы:
в
формулы: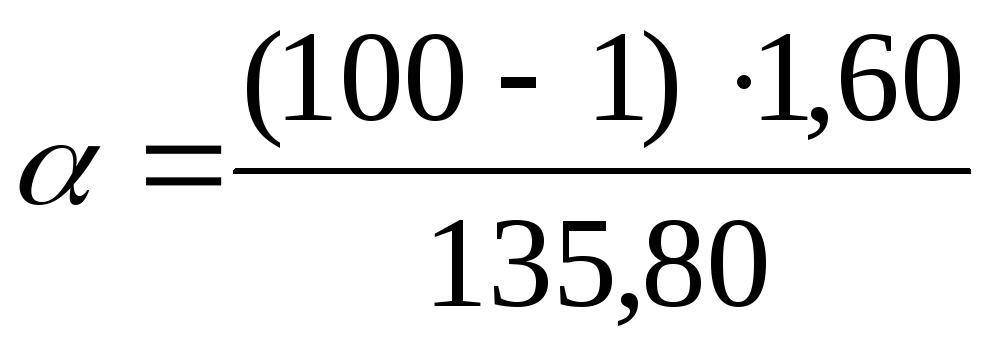 =
1,17;
=
1,17; =
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
=
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
Пример 3.3 . Среди 1000 семян пшеницы из поступившей на элеватор партии обнаружено 120 семян зараженных спорыньей. Необходимо определить вероятные границы генеральной доли зараженных семян в данной партии пшеницы.
Доверительные границы для генеральной доли при всех возможных ее значениях целесообразно определять по формуле:
 ,
,
Где n – число наблюдений; m – абсолютная численность одной из групп; t – нормированное отклонение.
Выборочная
доля зараженных семян равна
 или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
 )t
= 1,960.
)t
= 1,960.
Подставляем имеющиеся данные в формулу:
Отсюда
границы доверительного интервала
равны =
0,122–0,041 = 0,081, или 8,1%;
=
0,122–0,041 = 0,081, или 8,1%; = 0,122 + 0,041 = 0,163, или 16,3%.
= 0,122 + 0,041 = 0,163, или 16,3%.
Таким образом, с доверительной вероятностью 95% можно утверждать, что генеральная доля зараженных семян находится между 8,1 и 16,3%.
Пример 3.4 . Коэффициент вариации, характеризующий варьирование кальция (мг%) в сыворотке крови обезьян, оказался равным 10,6%. Объем выборки n = 100. Необходимо определить границы 95%-ного доверительного интервала для генерального параметра Cv .
Границы доверительного интервала для генерального коэффициента вариации Cv определяются по следующим формулам:
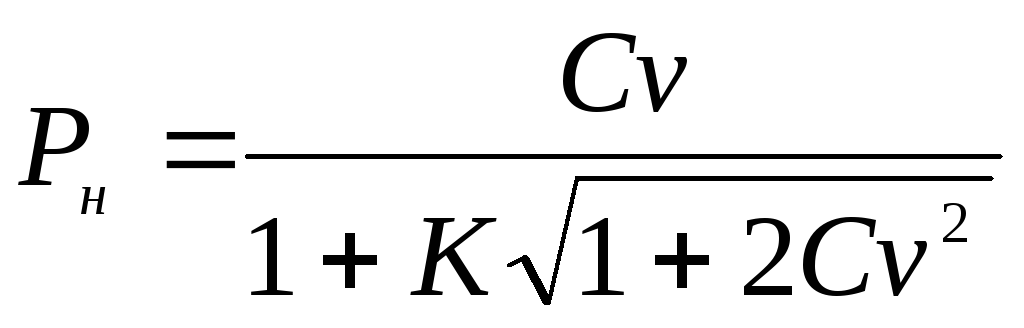 и
и
 ,
гдеK
промежуточная
величина, вычисляемая по формуле
,
гдеK
промежуточная
величина, вычисляемая по формуле
 .
.
Зная,
что при доверительной вероятности Р
= 95% нормированное отклонение (критерий
Стьюдента при k
=
 )t
= 1,960,
предварительно рассчитаем величину К:
)t
= 1,960,
предварительно рассчитаем величину К:
 .
.
 или
9,3%
или
9,3%
 или
12,3%
или
12,3%
Таким образом, генеральный коэффициент вариации с доверительной вероятностью 95% лежит в интервале от 9,3 до 12,3%. При повторных выборках коэффициент вариации не превысит 12,3% и не окажется ниже 9,3% в 95 случаях из 100.
Вопросы для самоконтроля:

Задачи для самостоятельного решения.
1. Средний процент жира в молоке за лактацию коров холмогорских помесей был следующим: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3,8. Установите доверительные интервалы для генеральной средней при доверительной вероятности 95% (20 баллов).
2. На 400 растениях гибридной ржи первые цветки появились в среднем на 70,5 день после посева. Среднее квадратическое отклонение было 6,9 дня. Определите ошибку средней и доверительные интервалы для генеральной средней и дисперсии при уровне значимости W = 0,05 и W = 0,01 (25 баллов).
3.
При изучении длины листьев 502 экземпляров
садовой земляники были получены следующие
данные:
 = 7,86 см; σ
= 1,32 см,
= 7,86 см; σ
= 1,32 см,
 =± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
=± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
4. При обследовании 150 взрослых мужчин средний рост был равен 167 см, а σ = 6 см. В каких пределах находится генеральная средняя и генеральная дисперсия с доверительной вероятностью 0,99 и 0,95? (25 баллов).
5.
Распределение кальция в сыворотке крови
обезьян характеризуется следующими
выборочными показателями:
 = 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
= 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
6. Было изучено общее содержание азота в плазме крови крыс-альбиносов в возрасте 37 и 180 дней. Результаты выражены в граммах на 100 см 3 плазмы. В возрасте 37 дней 9 крыс имели: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. В возрасте 180 дней 8 крыс имели: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1,12. Установите доверительные интервалы для разницы с доверительной вероятностью 0,95 (50 баллов).
7. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения кальция (мг%) в сыворотке крови обезьян, если для этого распределения объем выборки n = 100, статистическая ошибка выборочной дисперсии s σ 2 = 1,60 (40 баллов).
8. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения 40 колосков пшеницы по длине (σ 2 = 40, 87 мм 2). (25 баллов).
9. Курение считают основным фактором, предрасполагающим к обструктивным заболеваниям легких. Пассивное курение таким фактором не считается. Ученые усомнились в безвредности пассивного курения и исследовали проходимость дыхательных путей у некурящих, пассивных и активных курильщиков. Для характеристики состояния дыхательных путей взяли один из показателей функции внешнего дыхания – максимальную объемную скорость середины выдоха. Уменьшение этого показателя – признак нарушения проходимости дыхательных путей. Данные обследования приведены в таблице.
|
Число обследованных |
Максимальная объемная скорость середины выдоха, л/с |
||
|
Стандартное отклонение |
|||
|
Некурящие |
|||
|
работают в помещении, где не курят | |||
|
работают в накуренном помещении | |||
|
Курящие |
|||
|
выкуривающие небольшое число сигарет | |||
|
выкуривающие среднее число сигарет | |||
|
выкуривающие большое число сигарет | |||
По данным таблицы найдите 95% доверительные интервалы для генеральной средней и генеральной дисперсии для каждой из групп. В чем заключаются различия между группами? Результаты представьте графически (25 баллов).
10. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной дисперсии численности поросят в 64 опоросах, если статистическая ошибка выборочной дисперсии s σ 2 = 8, 25 (30 баллов).
11. Известно, что средняя масса кроликов составляет 2,1 кг. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной средней и дисперсии при n = 30, σ = 0,56 кг (25 баллов).
12.
У 100 колосьев измеряли озерненность
колоса (Х
),
длину колоса (Y
)
и массу зерна в колосе (Z
).
Найти доверительные интервалы для
генеральной средней и дисперсии при P
1
= 0,95, P
2
= 0,99, P
3
= 0,999, если
 = 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
= 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
13.
В отобранных случайным образом 100
колосьях озимой пшеницы подсчитывалось
число колосков. Выборочная совокупность
характеризовалась следующими показателями:
 = 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат (
= 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат ( )
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
)
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
14. Число ребер на раковинах ископаемого моллюска Orthambonites calligramma :
Известно, что n = 19, σ = 4,25. Определите границы доверительного интервала для генеральной средней и генеральной дисперсии при уровне значимости W = 0,01 (25 баллов).
15. Для определения удоев молока на молочно-товарной ферме ежедневно определялась продуктивность 15 коров. По данным за год каждая корова давала в среднем в сутки следующее количество молока (л): 22; 19; 25; 20; 27; 17; 30; 21; 18; 24; 26; 23; 25; 20; 24. Постройте доверительные интервалы для генеральной дисперсии и средней арифметической. Можно ли ожидать, что среднегодовой удой на каждую корову составит 10000 литров? (50 баллов).
16. С целью определения урожая пшеницы в среднем по агрохозяйству были проведены укосы на пробных участках площадью 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 и 2 га. Урожайность (ц/га) с участков составила 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 соответственно. Постройте доверительные интервалы для генеральных дисперсии и средней арифметической. Можно ли ожидать, что в среднем по агрохозяйству урожай составит 42 ц/га? (50 баллов).
Любая выборка дает лишь приближенное представление о генеральной совокупности, и все выборочные статистические характеристики (средняя, мода, дисперсия…) являются некоторым приближением или говорят оценкой генеральных параметров, которые вычислить в большинстве случаев не представляется возможным из-за недоступности генеральной совокупности (Рисунок 20).
Рисунок 20. Ошибка выборки
Но можно указать интервал, в котором с определенной долей вероятности лежит истинное (генеральное) значение статистической характеристики. Этот интервал называется д оверительный интервал (ДИ).
Так генеральное среднее значение с вероятностью 95% лежит в пределах
от до, (20)
где t – табличное значение критерия Стъюдента для α =0,05 и f = n -1
Может быть найден и 99% ДИ, в этом случае t выбирается для α =0,01.
Какое практическое значение имеет доверительный интервал?
Широкий доверительный интервал показывает, что выборочная средняя неточно отражает генеральную среднюю. Обычно это связано с недостаточным объемом выборки, или же с ее неоднородностью, т.е. большой дисперсией. И то и другое дают большую ошибку среднего и, соответственно, более широкий ДИ. И это является основанием вернуться на этап планирования исследования.
Верхние и нижние пределы ДИ дают оценку, будут ли результаты клинически значимы
Остановимся несколько подробнее на вопросе о статистической и клинической значимости результатов исследования групповых свойств. Вспомним, что задачей статистики является обнаружение хоть каких-либо отличий в генеральных совокупностях, опираясь на выборочные данные. Задачей клиницистов является обнаружение таких (не любых) различий, которые помогут диагностике или лечению. И не всегда статистические выводы являются основанием для клинических выводов. Так, статистически значимое снижение гемоглобина на 3 г/л не является поводом для беспокойства. И, наоборот, если какая-то проблема в организме человека не имеет массового характера на уровне всей популяции, это не основание для того, чтобы этой проблемой не заниматься.
|
Это положение рассмотрим на примере . Исследователи задались вопросом, не отстают ли в росте от своих сверстников мальчики, перенесшие некое инфекционное заболевание. С этой целью было проведено выборочное исследование, в котором приняли участие 10 мальчиков, перенесших эту болезнь. Результаты представлены в таблице 23. Таблица 23. Результаты статобработки
Из этих расчетов следует, что выборочный средний рост мальчиков 10 лет, перенесших некое инфекционное заболевание, близок к норме (132,5 см). Однако нижний предел доверительного интервала (126,6 см) свидетельствует о наличии 95% вероятности того, что истинный средний рост этих детей соответствует понятию «низкий рост», т.е. эти дети отстают в росте. В этом примере результаты расчетов доверительного интервала клинически значимы. |
|||||||||||||||||||




