Как вычислить дисперсию в статистике. Виды дисперсий. Математическое ожидание и дисперсия непрерывной случайной величины
Во многих случаях возникает необходимость ввести ещё одну числовую характеристику для измерения степени рассеивания, разброса значений , принимаемых случайной величиной ξ , вокруг её математического ожидания.
Определение. Дисперсией случайной величины ξ называется число.
D ξ = M(ξ-M ξ) 2 . (1)
Другими словами, дисперсия есть математическое ожидание квадрата отклонения значений случайной величины от её среднего значения.
называется средним квадратичным отклонением
величины ξ .
Если дисперсия характеризует средний размер квадрата отклонения ξ oт Mξ , то число можно рассматривать как некоторую среднюю характеристику самого отклонения, точнее, величины | ξ-Mξ |.
Из определения (1) вытекают следующие два свойства дисперсии.
1. Дисперсия постоянной величины равна нулю. Это вполне соответствует наглядному смыслу дисперсии, как «меры разброса».
Действительно, если
ξ = С, то Mξ = C и, значит Dξ = M(C-C ) 2 = M 0 = 0.
2. При умножении случайной величины ξ на постоянное число С её дисперсия умножается на C 2
D(Cξ ) = C 2 Dξ . (3)
Действительно
D(Cξ) = M(C
![]()
= M(C .
3. Имеет место, следующая формула для вычисления дисперсии:
![]() . (4)
. (4)
Доказательство этой формулы следует из свойств математического ожидания.
Мы имеем:

4. Если величины ξ 1 и ξ 2 независимы, то дисперсия их суммы равна сумме их дисперсий:
Доказательство . Для доказательства используем свойства математического ожидания. Пусть Mξ 1 = m 1 , Mξ 2 = m 2 , тогда.

Формула (5) доказана.
Так как дисперсия случайной величины есть по определению математическое ожидание величины (ξ -m ) 2 , где m = Mξ , то для вычисления дисперсии можно воспользоваться формулами, полученными в §7 гл.II.
Так, если ξ есть ДСВ с законом распределения
| x 1 | x 2 | ... |
| p 1 | p 2 | ... |
то будем иметь:
![]() . (7)
. (7)
Если ξ непрерывна случайная величина с плотностью распределения p(x) , тогда получим:
Dξ
= ![]() . (8)
. (8)
Если использовать формулу (4) для вычисления дисперсии, то можно получить другие формулы, а именно:
![]() , (9)
, (9)
если величина ξ дискретна, и
Dξ
= ![]() , (10)
, (10)
если ξ распределена с плотностью p (x ).
Пример 1 . Пусть величина ξ равномерно распределена на отрезке [a,b ]. Воспользовавшись формулой (10) получим:

Можно показать, что дисперсия случайной величины , распределенной по нормальному закону с плотностью
p(x) = , (11)
равна σ 2 .
Тем самым выясняется смысл параметра σ, входящего в выражение плотности (11) для нормального закона; σ ecть среднее квадратичное отклонение величины ξ .
Пример 2 . Найти дисперсию случайной величины ξ , распределенной по биномиальному закону.
Решение . Воспользовавшись представлением ξ в виде
ξ = ξ 1 + ξ 2 + ξ n (см. пример 2 §7 гл. II) и применяя формулу сложения дисперсий для независимых величин, получим
Dξ = Dξ 1 + Dξ 2 + Dξ n .
Дисперсия любой из величин ξ i (i = 1,2, n ) подсчитывается непосредственно:
Dξ i = M(ξ i ) 2 - (Mξ i ) 2 = 0 2 · q + 1 2 p - p 2 = p (1-p ) = pq .
Окончательно получаем
Dξ = npq , где q = 1 - p .
Среди множества показателей, которые применяются в статистике, нужно выделить расчет дисперсии. Следует отметить, что выполнение вручную данного вычисления – довольно утомительное занятие. К счастью, в приложении Excel имеются функции, позволяющие автоматизировать процедуру расчета. Выясним алгоритм работы с этими инструментами.
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г . Синтаксис этого выражения имеет следующий вид:
ДИСП.Г(Число1;Число2;…)
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.


Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
ДИСП.В(Число1;Число2;…)
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.


Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Вычислим в MS EXCEL дисперсию и стандартное отклонение выборки. Также вычислим дисперсию случайной величины, если известно ее распределение.
Сначала рассмотрим дисперсию , затем стандартное отклонение .
Дисперсия выборки
Дисперсия выборки (выборочная дисперсия, sample variance ) характеризует разброс значений в массиве относительно .
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что дисперсия выборки это сумма квадратов отклонений каждого значения в массиве от среднего , деленная на размер выборки минус 1.
дисперсии выборки используется функция ДИСП() , англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог ДИСП.В() , англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция ДИСП.Г(), англ. название VARP, т.е. Population VARiance, которая вычисляет дисперсию для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у ДИСП.В() , у ДИСП.Г() в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция ДИСПР() .
Дисперсию выборки
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)
=(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1
) –
Дисперсия выборки равна 0, только в том случае, если все значения равны между собой и, соответственно, равны среднему значению . Обычно, чем больше величина дисперсии , тем больше разброс значений в массиве.
Дисперсия выборки является точечной оценкой дисперсии распределения случайной величины, из которой была сделана выборка . О построении доверительных интервалов при оценке дисперсии можно прочитать в статье .
Дисперсия случайной величины
Чтобы вычислить дисперсию случайной величины, необходимо знать ее .
Для дисперсии случайной величины Х часто используют обозначение Var(Х). Дисперсия равна квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X)) 2 ]
дисперсия вычисляется по формуле:

где x i – значение, которое может принимать случайная величина, а μ – среднее значение (), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет , то дисперсия вычисляется по формуле:

Размерность дисперсии соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг 2 . Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из дисперсии – стандартное отклонение .
Некоторые свойства дисперсии :
Var(Х+a)=Var(Х), где Х - случайная величина, а - константа.
Var(aХ)=a 2 Var(X)
Var(Х)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)-2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Это свойство дисперсии используется в статье про линейную регрессию .
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y - случайные величины, Cov(Х;Y) - ковариация этих случайных величин.
Если случайные величины независимы (independent), то их ковариация равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе .
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1) 2 Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения .
Стандартное отклонение выборки
Стандартное отклонение выборки - это мера того, насколько широко разбросаны значения в выборке относительно их .
По определению, стандартное отклонение равно квадратному корню из дисперсии :

Стандартное отклонение не учитывает величину значений в выборке , а только степень рассеивания значений вокруг их среднего . Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется Коэффициент вариации (Coefficient of Variation, CV) - отношение Стандартного отклонения к среднему арифметическому , выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления Стандартного отклонения выборки используется функция =СТАНДОТКЛОН() , англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог =СТАНДОТКЛОН.В() , англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция СТАНДОТКЛОН.Г() , англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет стандартное отклонение для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у СТАНДОТКЛОН.В() , у СТАНДОТКЛОН.Г() в знаменателе просто n.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера
)
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1))
=КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Другие меры разброса
Функция КВАДРОТКЛ() вычисляет сумму квадратов отклонений значений от их среднего . Эта функция вернет тот же результат, что и формула =ДИСП.Г(Выборка )*СЧЁТ(Выборка ) , где Выборка - ссылка на диапазон, содержащий массив значений выборки (). Вычисления в функции КВАДРОТКЛ() производятся по формуле:

Функция СРОТКЛ() является также мерой разброса множества данных. Функция СРОТКЛ() вычисляет среднее абсолютных значений отклонений значений от среднего . Эта функция вернет тот же результат, что и формула =СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка) , где Выборка - ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции СРОТКЛ () производятся по формуле:

Наряду с изучением вариации признака по всей по всей совокупности в целом часто бывает необходимо проследить количественные изменения признака по группам, на которые разделяется совокупность, а также и между группами. Такое изучение вариации достигается посредством вычисления и анализа различных видов дисперсии.
Выделяют дисперсию общую, межгрупповую и внутригрупповую
.
Общая дисперсия σ 2
измеряет вариацию признака по всей совокупности под влиянием всех факторов, обусловивших эту вариацию, .
Межгрупповая дисперсия (δ) характеризует систематическую вариацию, т.е. различия в величине изучаемого признака, возникающие под влиянием признака-фактора, положенного в основание группировки. Она рассчитывается по формуле:
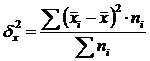 .
.
Внутригрупповая дисперсия (σ)
отражает случайную вариацию, т.е. часть вариации, происходящую под влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Она вычисляется по формуле:
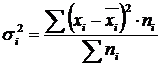 .
.
Средняя из внутригрупповых дисперсий
:  .
.
Существует закон, связывающий 3 вида дисперсии. Общая дисперсия равна сумме средней из внутригрупповых и межгрупповой дисперсии: ![]() .
.
Данное соотношение называют правилом сложения дисперсий
.
В анализе широко используется показатель, представляющий собой долю межгрупповой дисперсии в общей дисперсии. Он носит название эмпирического коэффициента детерминации (η 2):
.
Корень квадратный из эмпирического коэффициента детерминации носит название эмпирического корреляционного отношения (η)
:
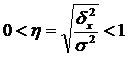 .
.
Оно характеризует влияние признака, положенного в основание группировки, на вариацию результативного признака. Эмпирическое корреляционное отношение изменяется в пределах от 0 до 1.
Покажем его практическое использование на следующем примере (табл. 1).
Пример №1 . Таблица 1 - Производительность труда двух групп рабочих одного из цехов НПО «Циклон»
Рассчитаем общую и групповые средние и дисперсии:
Исходные данные для вычисления средней из внутригрупповых и межгрупповой дисперсии представлены в табл. 2.
Таблица 2
Расчет и δ 2 по двум группам рабочих.
|
Группы рабочих | Численность рабочих, чел. | Средняя, дет./смен. | Дисперсия |
| Прошедшие техническое обучение | 5 | 95 | 42,0 |
| Не прошедшие техническое обучение | 5 | 81 | 231,2 |
| Все рабочие | 10 | 88 | 185,6 |
 .
.
Межгрупповая дисперсия
Общая дисперсия:
Таким образом, эмпирическое корреляционное соотношение: .
Наряду с вариацией количественных признаков может наблюдаться и вариация качественных признаков. Такое изучение вариации достигается посредством вычисления следующих видов дисперсий:
Внутригрупповая дисперсия доли определяется по формуле
где n i – численность единиц в отдельных группах.Доля изучаемого признака во всей совокупности, которая определяется по формуле:
Три вида дисперсии связаны между собой следующим образом:
Это соотношение дисперсий называется теоремой сложения дисперсий доли признака.




