Методы математической статистики для трех выборок. Основы математической статистики. Полезная медицинская информация обычно скрыта в массе необработанных данных. Необходимо сконцентрировать информацию, которая содержится в них, и представить данные так, ч
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
Введение
Математическая статистика -- наука о математических методах систематизации и использования статистических данных для научных и практических выводов. Во многих своих разделах математическая статистика опирается на теорию вероятностей позволяющую оценить надежность и точность выводов делаемых на основании ограниченного статистического материала (напр. оценить необходимый объем выборки для получения результатов требуемой точности при выборочном обследовании).
В теории вероятностей рассматриваются случайные величины с заданным распределением или случайные эксперименты свойства которых целиком известны. Предмет теории вероятностей -- свойства и взаимосвязи этих величин (распределений).
Но часто эксперимент представляет собой черный ящик выдающий лишь некие результаты по которым требуется сделать вывод о свойствах самого эксперимента. Наблюдатель имеет набор числовых (или их можно сделать числовыми) результатов полученных повторением одного и того же случайного эксперимента в одинаковых условиях.
При этом возникают например следующие вопросы: Если мы наблюдаем одну случайную величину -- как по набору ее значений в нескольких опытах сделать как можно более точный вывод о ее распределении? математический статистика дисперсия гистограмма
Примером такой серии экспериментов может служить социологический опрос набор экономических показателей или наконец последовательность гербов и решек при тысячекратном подбрасывании монеты. Все вышеприведенные факторы обуславливают актуальность и значимость тематики работы на современном этапе направленной на глубокое и всестороннее изучение основных понятий математической статистики.
1. Предмет и метод математической статистики
В зависимости от математической природы конкретных результатов наблюдений статистика математическая делится на статистику чисел многомерный статистический анализ анализ функций (процессов) и временных рядов статистику объектов нечисловой природы. Существенная часть статистики математической основана на вероятностных моделях. Выделяют общие задачи описания данных оценивания и проверки гипотез. Рассматривают и более частные задачи связанные с проведением выборочных обследований восстановлением зависимостей построением и использованием классификаций (типологий) и др.
Для описания данных строят таблицы диаграммы иные наглядные представления например корреляционные поля. Вероятностные модели обычно не применяются. Некоторые методы описания данных опираются на продвинутую теорию и возможности современных компьютеров. К ним относятся в частности кластер-анализ нацеленный на выделение групп объектов похожих друг на друга и многомерное шкалирование позволяющее наглядно представить объекты на плоскости в наименьшей степени исказив расстояния между ними.
Методы оценивания и проверки гипотез опираются на вероятностные модели порождения данных. Эти модели делятся на параметрические и непараметрические. В параметрических моделях предполагается что изучаемые объекты описываются функциями распределения зависящими от небольшого числа (1-4) числовых параметров. В непараметрических моделях функции распределения предполагаются произвольными непрерывными. В статистике математической оценивают параметры и характеристики распределения (математическое ожидание медиану дисперсию квантили и др.) плотности и функции распределения зависимости между переменными (на основе линейных и непараметрических коэффициентов корреляции а также параметрических или непараметрических оценок функций выражающих зависимости) и др. Используют точечные и интервальные (дающие границы для истинных значений) оценки.
В математической статистике есть общая теория проверки гипотез и большое число методов посвященных проверке конкретных гипотез. Рассматривают гипотезы о значениях параметров и характеристик о проверке однородности (то есть о совпадении характеристик или функций распределения в двух выборках) о согласии эмпирической функции распределения с заданной функцией распределения или с параметрическим семейством таких функций о симметрии распределения и др.
Большое значение имеет раздел математической статистики связанный с проведением выборочных обследований со свойствами различных схем организации выборок и построением адекватных методов оценивания и проверки гипотез.
Задачи восстановления зависимостей активно изучаются более 200 лет с момента разработки К. Гауссом в 1794 г. метода наименьших квадратов. В настоящее время наиболее актуальны методы поиска информативного подмножества переменных и непараметрические методы.
Разработка методов аппроксимации данных и сокращения размерности описания была начата более 100 лет назад когда К. Пирсон создал метод главных компонент. Позднее были разработаны факторный анализ и многочисленные нелинейные обобщения.
Различные методы построения (кластер-анализ) анализа и использования (дискриминантный анализ) классификаций (типологий) именуют также методами распознавания образов (с учителем и без) автоматической классификации и др.
Математические методы в статистике основаны либо на использовании сумм (на основе Центральной Предельной Теоремы теории вероятностей) или показателей различия (расстояний метрик) как в статистике объектов нечисловой природы. Строго обоснованы обычно лишь асимптотические результаты. В настоящее время компьютеры играют большую роль в математической статистике. Они используются как для расчетов так и для имитационного моделирования (в частности в методах размножения выборок и при изучении пригодности асимптотических результатов).
1.1 Основные понятия математической статистики
Исключительно важную роль в анализе многих психолого-педагогических явлений играют средние величины, представляющие собой обобщенную характеристи ку качественно однородной совокупности по определенному количественно му признаку. Нельзя, например, вычислить среднюю специальность или среднюю национальность студентов вуза, так как это качест венно разнородные явления. Зато можно и нужно определить в среднем числовую характеристику их успеваемости (средний балл), эффек тивности методических систем и приемов и т. д.
В психолого-педагогических исследованиях обычно применяются различные виды средних величин: средняя арифметическая, сред няя геометрическая, медиана, мода и другие. Наиболее распространенными являются средняя арифметическая, медиана и мода.
Средняя арифметическая применяется в тех случаях, когда между определяю щим свойством и данным признаком имеется прямо пропорциональная зави симость (например, при улучшении показателей работы учебной группы улучшаются показатели работы каждого ее члена).
Средняя арифметическая представляет собой частное от деления сум мы величин на их число и вычисляется по формуле:
Размещено на http://www.allbest.ru/
где Х - средняя арифметическая; X1, X2, Х3 ... Хn - результаты отдельных наблюдений (приемов, действий),
n - количество наблюдений (приемов, действий),
Сумма результатов всех наблюдений (приемов, действий).
Медианой (Ме) называется мера среднего положения, характеризующая значение признака на упорядоченной (построенной по признаку возрастания или убывания) шкале, которое соответствует середине исследуемой совокупности. Медиана может быть определена для порядковых и количественных признаков. Место расположения этого значения определяется по формуле:
Место медианы = (n + 1) / 2
Например. По результатам исследования установлено, что:
На “отлично” учатся - 5 человек из участвующих в эксперименте;
На “хорошо” учатся - 18 человек;
На “удовлетворительно” - 22 человека;
На “неудовлетворительно” - 6 человек.
Так как всего в эксперименте принимало участие N = 54 человека, то середина выборки равна человек. Отсюда делается вывод, что больше половины обучающихся учатся ниже оценки “хорошо”, то есть медиана больше “удовлетворительно”, но меньше “хорошо”.
Мода (Мо) - наиболее часто встречающееся типичное значение признака среди других значений. Она соответствует классу с максимальной частотой. Этот класс называется модальным значением.
Например.
Если на вопрос анкеты: “укажите степень владения иностранным языком”, ответы распределились:
1 - владею свободно - 25
2 - владею в достаточной степени для общения - 54
3 - владею, но испытываю трудности при общении - 253
4 - понимаю с трудом - 173
5 - не владею - 28
Очевидно, что наиболее типичным значением здесь является - “владею, но испытываю трудности при общении”, которое и будет модальным. Таким образом, мода равна - 253.
Важное значение при использовании в психолого-педагогическом исследовании математических методов уделяется расчету дисперсии и среднеквадратических (стандартных) отклонений.
Дисперсия равна среднему квадрату отклонений значения варианты от среднего значения. Она выступает как одна из характеристик индивидуальных результатов разброса значений исследуемой переменной (например, оценок учащихся) вокруг среднего значения. Вычисление дисперсии осуществляется путем определения: отклонения от среднего значения; квадрата указанного отклонения; суммы квадратов отклонения и среднего значения квадрата отклонения.
Значение дисперсии используется в различных статистических расчетах, но не имеет непосредственного наблюдаемого характера. Величиной, непосредственно связанной с содержанием наблюдаемой переменной, является среднее квадратическое отклонение.
Среднее квадратичное отклонение подтверждает типичность и показательность средней арифметической, отражает меру колебания численных значений признаков, из которых выводится средняя величина. Оно равно корню квадратному из дисперсии и определяется по формуле:
(2)Размещено на http://www.allbest.ru/
где: - средняя квадратическая. При малом числе наблюдения (действий) - менее 100 - в значении формулы следует ставить не “N”, а “N - 1”.
Средняя арифметическая и средняя квадратическая являются основны ми характеристиками полученных результатов в ходе исследования. Они позволяют обобщить данные, сравнить их, установить преимущества одной психолого-педагогической системы (программы) над другой.
Среднее квадратическое (стандартное) отклонение широко применяется как мера разброса для различных характеристик.
Оценивая результаты исследования важно определить рассеивание случайной величины около среднего значения. Это рассеивание описывается с помощью закона Гауса (закона нормального распределения вероятности случайной величины). Суть закона заключается в том, что при измерении некоторого признака в данной совокупности элементов всегда имеют место отклонения в обе стороны от нормы вследствие множества неконтролируемых причин, при этом, чем больше отклонения, тем реже они встречаются.
При дальнейшей обработке данных могут быть выявлены: коэффициент вариации (устойчивости) исследуемого явления, представляющий собой процентное отношение среднеквадратического отклонения к средней ариф метической; мера косости, показывающая, в какую сторону направлено преимущественное число отклонений; мера крутости, которая показывает степень скопления значений случайной величины около среднего и др. Все эти статистические данные помогают более полно выявить признаки изучаемых явлений.
Меры связи между переменными. Связи (зависимости) между двумя и более переменными в статистике называют корреляцией. Она оценивается с помощью значения коэффициента корреляции, который является мерой степени и величины этой связи.
Коэффициентов корреляции много. Рассмотрим лишь часть из них, которые учитывают наличие линейной связи между переменными. Их выбор зависит от шкал измерения переменных, зависимость между которыми необходимо оценить. Наиболее часто в психологии и педагогике применяются коэффициенты Пирсона и Спирмена.
1.2 Основные понятия выборочного метода
Пусть -- случайная величина наблюдаемая в случайном эксперименте. Предполагается что вероятностное пространство задано (и не будет нас интересовать).
Будем считать что проведя раз этот эксперимент в одинаковых условиях мы получили числа -- значения этой случайной величины в первом втором и т.д. экспериментах. Случайная величина имеет некоторое распределение которое нам частично или полностью неизвестно.
Рассмотрим подробнее набор называемый выборкой.
В серии уже произведенных экспериментов выборка -- это набор чисел. Но если эту серию экспериментов повторить еще раз то вместо этого набора мы получим новый набор чисел. Вместо числа появится другое число -- одно из значений случайной величины. То есть (и и и т.д.) -- переменная величина которая может принимать те же значения что и случайная величина и так же часто (с теми же вероятностями). Поэтому до опыта -- случайная величина одинаково распределенная с а после опыта -- число которое мы наблюдаем в данном первом эксперименте т.е. одно из возможных значений случайной величины.
Выборка объема -- это набор из независимых и одинаково распределенных случайных величин («копий ») имеющих как и распределение.
Что значит «по выборке сделать вывод о распределении»? Распределение характеризуется функцией распределения плотностью или таблицей набором числовых характеристик -- и т.д. По выборке нужно уметь строить приближения для всех этих характеристик.
1.3 Выборочное распределение
Рассмотрим реализацию выборки на одном элементарном исходе -- набор чисел. На подходящем вероятностном пространстве введем случайную величину принимающую значения с вероятностями по (если какие-то из значений совпали сложим вероятности соответствующее число раз).
Распределение величины называют эмпирическим или выборочным распределением. Вычислим математическое ожидание и дисперсию величины и введем обозначения для этих величин:
Точно так же вычислим и момент порядка
В общем случае обозначим через величину
Если при построении всех введенных нами характеристик считать выборку набором случайных величин то и сами эти характеристики -- -- станут величинами случайными. Эти характеристики выборочного распределения используют для оценки (приближения) соответствующих неизвестных характеристик истинного распределения.
Причина использования характеристик распределения для оценки характеристик истинного распределения (или) -- в близости этих распределений при больших.
Рассмотрим для примера подбрасываний правильного кубика. Пусть -- количество очков выпавших при -м броске. Предположим что единица в выборке встретится раз двойка -- раз и т.д. Тогда случайная величина будет принимать значения 1 6 с вероятностями соответственно. Но эти пропорции с ростом приближаются к согласно закону больших чисел. То есть распределение величины в некотором смысле сближается с истинным распределением числа очков выпадающих при подбрасывании правильного кубика.
1.4 Эмпирическая функция распределения гистограмма
Поскольку неизвестное распределение можно описать например его функцией распределения построим по выборке «оценку» для этой функции.
Определение 1. Эмпирической функцией распределения построенной по выборке объема называется случайная функция при каждом равная
Напоминание: Случайная функция
называется индикатором события. При каждом это -- случайная величина имеющая распределение Бернулли с параметром
Иначе говоря, при любом значение равное истинной вероятности случайной величине быть меньше оценивается долей элементов выборки меньших.
Если элементы выборки упорядочить по возрастанию (на каждом элементарном исходе) получится новый набор случайных величин называемый вариационным рядом:
Элемент называется -м членом вариационного ряда или -й порядковой статистикой.
Эмпирическая функция распределения имеет скачки в точках выборки величина скачка в точке равна где -- количество элементов выборки совпадающих с.
Можно построить эмпирическую функцию распределения по вариационному ряду:
Другой характеристикой распределения является таблица (для дискретных распределений) или плотность (для абсолютно непрерывных). Эмпирическим или выборочным аналогом таблицы или плотности является так называемая гистограмма. Гистограмма строится по группированным данным. Предполагаемую область значений случайной величины (или область выборочных данных) делят независимо от выборки на некоторое количество интервалов (не обязательно одинаковых). Пусть -- интервалы на прямой называемые интервалами группировки. Обозначим для через число элементов выборки попавших в интервал:
На каждом из интервалов строят прямоугольник площадь которого пропорциональна. Общая площадь всех прямоугольников должна равняться единице. Пусть -- длина интервала. Высота прямоугольника над равна
Полученная фигура называется гистограммой.
Разобьем отрезок на 4 равных отрезка. В отрезок попали 4 элемента выборки в -- 6 в -- 3 и в отрезок попали 2 элемента выборки. Строим гистограмму (рис. 2). На рис. 3 -- тоже гистограмма для той же выборки но при разбиении области на 5 равных отрезков.
В курсе «Эконометрика» утверждается, что наилучшим числом интервалов группировки («формула Стерджесса») является
Здесь -- десятичный логарифм, поэтому
т.е. при увеличении выборки вдвое число интервалов группировки увеличивается на 1. Заметим что чем больше интервалов группировки, тем лучше. Но если брать число интервалов скажем порядка,то с ростом гистограмма не будет приближаться к плотности.
Справедливо следующее утверждение:
Если плотность распределения элементов выборки является непрерывной функцией, то при так что имеет место поточечная сходимость по вероятности гистограммы к плотности.
Так что выбор логарифма разумен, но не является единственно возможным.
Размещено на Allbest.ru
...Подобные документы
Построение полигона относительных частот, эмпирической функции распределения, кумулянты и гистограммы. Расчет точечных оценок неизвестных числовых характеристик. Проверка гипотезы о виде распределения для простого и сгруппированного ряда распределения.
курсовая работа , добавлен 28.09.2011
Предмет, методы и понятия математической статистики, ее взаимосвязь с теорией вероятности. Основные понятия выборочного метода. Характеристика эмпирической функции распределения. Понятие гистограммы, принцип ее построения. Выборочное распределение.
учебное пособие , добавлен 24.04.2009
Классификация случайных событий. Функция распределения. Числовые характеристики дискретных случайных величин. Закон равномерного распределения вероятностей. Распределение Стьюдента. Задачи математической статистики. Оценки параметров совокупности.
лекция , добавлен 12.12.2011
Оценки параметров распределения, наиболее важные распределения, применяемые в математической статистике: нормальное распределение, распределения Пирсона, Стьюдента, Фишера. Факторное пространство, формулирование цели эксперимента и выбор откликов.
реферат , добавлен 01.01.2011
Числовые характеристики выборки. Статистический ряд и функция распределения. Понятие и графическое представление статистической совокупности. Метод наибольшего правдоподобия для нахождения плотности распределения. Применение метода наименьших квадратов.
контрольная работа , добавлен 20.02.2011
Задачи математической статистики. Распределение случайной величины на основе опытных данных. Эмпирическая функция распределения. Статистические оценки параметров распределения. Нормальный закон распределения случайной величины, проверка гипотезы.
курсовая работа , добавлен 13.10.2009
Статистическая обработка данных контроля времени (в часах) работы компьютерного класса в день. Полигон абсолютных частот. Построение графика эмпирической функции распределения и огибающей гистограммы. Теоретическое распределение генеральной совокупности.
контрольная работа , добавлен 23.08.2015
Обработка результатов информации по транспортным и технологическим машинам методом математической статистики. Определение интегральной функции нормального распределения, функции закона Вейбула. Определение величины сдвига к началу распределения параметра.
контрольная работа , добавлен 05.03.2017
Понятие математической статистики как науки о математических методах систематизации и использования статистических данных для научных и практических выводов. Точечные оценки параметров статистических распределений. Анализ вычисления средних величин.
курсовая работа , добавлен 13.12.2014
Основные понятия математической статистики, интервальные оценки. Метод моментов и метод максимального правдоподобия. Проверка статистических гипотез о виде закона распределения при помощи критерия Пирсона. Свойства оценок, непрерывные распределения.
Методы математической статистики
1. Введение
Математической статистикой называется наука, занимающаяся разработкой методов получения, описания и обработки опытных данных с целью изучения закономерностей случайных массовых явлений.
В математической статистике можно выделить два направления: описательную статистику и индуктивную статистику (статистический вывод). Описательная статистика занимается накоплением, систематизацией и представлением опытных данных в удобной форме. Индуктивная статистика на основе этих данных позволяет сделать определенные выводы относительно объектов, о которых собраны данные, или оценки их параметров.
Типичными направлениями математической статистики являются:
1) теория выборок;
2) теория оценок;
3) проверка статистических гипотез;
4) регрессионный анализ;
5) дисперсионный анализ.
В основе математической статистики лежит ряд исходных понятий без которых невозможно изучение современных методов обработки опытных данных. В ряд первых из них можно поставить понятие генеральной совокупности и выборки.
При массовом промышленном производстве часто нужно без проверки каждого выпускаемого изделия установить, соответствует ли качество продукции стандартам. Так как количество выпускаемой продукции очень велико или проверка продукции связана с приведением ее в негодность, то проверяется небольшое количество изделий. На основе этой проверки нужно дать заключение о всей серии изделий. Конечно нельзя утверждать, что все транзисторы из партии в 1 млн. штук годны или негодны, проверив один из них. С другой стороны, поскольку процесс отбора образцов для испытаний и сами испытания могут оказаться длительными по времени и привести к большим затратам, то объем проверки изделий должен быть таким, чтобы он смог дать достоверное представление о всей партии изделий, будучи минимальных размеров. С этой целью введем ряд понятий.
Вся совокупность изучаемых объектов или экспериментальных данных называется генеральной совокупностью. Будем обозначать через N число объектов или количество данных, составляющих генеральную совокупность. Величину N называют объемом генеральной совокупности. Если N>>1, то есть N очень велико, то обычно считают N = ¥.
Случайной выборкой или просто выборкой называют часть генеральной совокупности, наугад отобранную из нее. Слово "наугад" означает, что вероятности выбора любого объекта из генеральной совокупности одинакова. Это важное предположение, однако, часто трудно это проверить на практике.
Объемом выборки называют число объектов или количество данных, составляющих выборку, и обозначают n . В дальнейшем будем считать, что элементам выборки можно приписать соответственно числовые значения х 1 , х 2 , ... х n . Например, в процессе контроля качества производимых биполярных транзисторов это могут быть измерения их коэффициента усиления по постоянному току.
2. Числовые характеристики выборки
2.1 Выборочное среднее
Для конкретной выборки объема n ее выборочное среднее
определяется соотношениемгде х i – значение элементов выборки. Обычно требуется описать статистические свойства произвольных случайных выборок, а не одной из них. Это значит, что рассматривается математическая модель, которая предполагает достаточно большое количество выборок объема n. В этом случае элементы выборки рассматриваются как случайные величины Х i , принимающие значения х i с плотностью вероятностей f(x), являющейся плотностью вероятностей генеральной совокупности. Тогда выборочное среднее также является случайной величиной
равнойКак и ранее будем обозначать случайные величины прописными буквами, а значения случайных величин – строчными.
Среднее значение генеральной совокупности, из которой производится выборка, будем называть генеральным средним и обозначать m x . Можно ожидать, что если объем выборки значителен, то выборочное среднее не будет заметно отличаться от генерального среднего. Поскольку выборочное среднее является случайной величиной, для нее можно найти математическое ожидание:

Таким образом, математическое ожидание выборочного среднего равно генеральному среднему. В этом случае говорят, что выборочное среднее является несмещенной оценкой генерального среднего. В дальнейшем мы вернемся к этому термину. Так как выборочное среднее является случайной величиной, флуктуирующей вокруг генерального среднего, то желательно оценить эту флуктуацию с помощью дисперсии выборочного среднего. Рассмотрим выборку, объем которой n значительно меньше объема генеральной совокупности N (n << N). Предположим, что при формировании выборки характеристики генеральной совокупности не меняются, что эквивалентно предположению N = ¥. Тогда
Случайные величины Х i и X j (i¹j) можно считать независимыми, следовательно,

Подставим полученный результат в формулу для дисперсии:
где s 2 – дисперсия генеральной совокупности.
Из этой формулы следует, что с увеличением объема выборки флуктуации среднего выборочного около среднего генерального уменьшаются как s 2 /n. Проиллюстрируем сказанное примером. Пусть имеется случайный сигнал с математическим ожиданием и дисперсией соответственно равными m x = 10, s 2 = 9.
Отсчеты сигнала берутся в равноотстоящие моменты времени t 1 , t 2 , ... ,
 X(t)
X(t)
X 1
t 1 t 2 . . . t n t
Так как отсчеты являются случайными величинами, то будем их обозначать X(t 1), X(t 2), . . . , X(t n).
Определим количество отсчетов, чтобы среднее квадратическое отклонение оценки математического ожидания сигнала не превысило 1% его математического ожидания. Поскольку m x = 10, то нужно, чтобы
С другой стороны поэтому или Отсюда получаем, что n ³ 900 отсчетов.2.2 Выборочная дисперсия
По выборочным данным важно знать не только выборочное среднее, но и разброс выборочных значений около выборочного среднего. Если выборочное среднее является оценкой генерального среднего, то выборочная дисперсия должна быть оценкой генеральной дисперсии. Выборочная дисперсия
для выборки, состоящей из случайных величин определяется следующим образом
Используя это представление выборочной дисперсии, найдем ее математическое ожидание
Рассмотрим некоторые понятия и основные подходы к классификации погрешностей. По способу вычисления погрешности можно подразделить на абсолютные и относительные.
Абсолютная погрешность равна разности среднего измерения величины х и истинного значения этой величины:
В отдельных случаях, если это необходимо, рассчитывают погрешности единичных определений:

Заметим, что измеренной величиной в химическом анализе может быть как содержание компонента, так и аналитический сигнал. В зависимости от того, завышает или занижает погрешность результат анализа, погрешности могут быть положительные и отрицательные.
Относительная погрешность может быть выражена в долях или процентах и обычно знака не имеет:
 или
или

Можно классифицировать погрешности по источникам их происхождения. Так как источников погрешностей чрезвычайно много, то их классификация не может быть однозначной.
Чаще всего погрешности классифицируют по характеру причин, их вызывающих. При этом погрешности делят на систематиче ские и случайные, выделяют также промахи (или грубые погрешности).
К систематическим относят погрешности, которые вызваны постоянно действующей причиной, постоянны во всех измерениях или меняются по постоянно действующему закону, могут быть выявлены и устранены.
Случайные погрешности, причины появления которых неизвестны, могут быть оценены методами математической статистики.
Промах - это погрешность, резко искажающая результат анализа и обычно легко обнаруживаемая, вызванная, как правило, небрежностью или некомпетентностью аналитика. На рис. 1.1 представлена схема, поясняющая понятия систематических и погрешностей и промахов. Прямая 1 отвечает тому идеальному случаю, когда во всех N определениях отсутствуют систематические и случайные погрешности. Линии 2 и 3 тоже идеализированные примеры химического анализа. В одном случае (прямая 2) полностью отсутствуют случайные погрешности, но все N определений имеют постоянную отрицательную систематическую погрешность Δх; в другом случае (линия 3) полностью отсутствует систематическая погрешность. Реальную ситуацию отражает линия 4: имеются как случайные, так и систематические погрешности.

Рис. 4.2.1 Систематические и случайные погрешности химического анализа.
Деление погрешностей на систематические и случайные в известной степени условно.
Систематические погрешности одной выборки результатов при рассмотрении большего числа данных могут переходить в случайные. Например, систематическая погрешность, обусловленная неправильными показаниями прибора, при измерении аналитического сигнала на разных приборах в разных лабораториях переходит в случайную.
Воспроизводимость характеризует степень близости друг к другу единичных определений, рассеяние единичных результатов относительно среднего (рис. 1.2).

Рис. 4.2..2. Воспроизводимость и правильность химического анализа
В отдельных случаях наряду с термином «воспроизводимость» используют термин «сходимость». При этом под сходимостью понимают рассеяние результатов параллельных определений, а под воспроизводимостью - рассеяние результатов, полученных разными методами, в разных лабораториях, в разное время и т. п.
Правильность - это качество химического анализа, отражающее близость к нулю систематической погрешности. Правильность характеризует отклонение полученного результата анализа от истинного значения измеряемой величины (см. рис.1.2).
Генеральная совокупность - гипотетическая совокупность всех мыслимых результатов от -∞ до +∞;
Анализ
экспериментальных данных показывает,
что большие по значению погрешности
наблюдаются реже
,
чем малые. Отмечается также, что при
увеличении числа наблюдений одинаковые
погрешности разного знака встречаются
одинаково
часто. Эти и другие свойства случайных
погрешностей описываются нормальным
распределением или уравнением
Гаусса,
которое
описывает плотность вероятности  .
.


где х -значение случайной величины;
μ – генеральное среднее (математическое ожидание -постоянный параметр);
Математическое
ожидание
-
для
непрерывной случайной величины
представляет собой предел, к которому
стремится среднее
 при неограниченном увеличении выборки.
Таким образом, математическое ожидание
является средним значением для всей
генеральной совокупности в целом, иногда
его называют
генеральным
средним.
при неограниченном увеличении выборки.
Таким образом, математическое ожидание
является средним значением для всей
генеральной совокупности в целом, иногда
его называют
генеральным
средним.
σ 2 -дисперсия (постоянный параметр) - характеризует рассеяние случайной величины относительно своего математического ожидания;
σ – стандартное отклонение.
Дисперсия – характеризует рассеяние случайной величины относительно своего математического ожидания.
Выборочная совокупность (выборка) - реальное число (n) результатов, которое имеет исследователь, n = 3 ÷ 10.
Нормальный закон распределения неприемлем для обработки малого числа изменений выборочной совокупности (обычно 3 – 10) – даже если генеральная совокупность в целом распределена нормально. Для малых выборок вместо нормального распределения используют распределение Стьюдента (t – распределение) , которое связывает между собой три основные характеристики выборочной совокупности –
Ширину доверительного интервала;
Соответствующую ему вероятность;
Объем выборочной совокупности.
Перед обработкой данных с применением методов математической статистики необходимо выявить промахи (грубые ошибки) и исключить их из числа рассматриваемых результатов. Одним из наиболее простых является метод выявления промахов с применением Q – критерия с числом измерений n < 10:

где R = х макс - х мин – размах варьирования; х 1 – подозрительно выделяющееся значение; х 2 – результат единичного определения, ближайший по значению к х 1 .
Полученное значение сравнивают с критическим значением Q крит при доверительной вероятности Р = 0,95. Если Q > Q крит, выпадающий результат является промахом и его отбрасывают.
Основные
характеристики выборочной совокупности
.
Для выборки из n
результатов
рассчитывают среднее,
 :
:

и дисперсию , характеризующую рассеяние результатов относительно среднего:

Дисперсия в явном виде не может быть использована для количественной характеристики рассеяния результатов, поскольку ее размерность не совпадает с размерностью результата анализа. Для характеристики рассеяния используют стандартное отклонение, S .

Эту величину называют также средним квадратичным (или квадратическим) отклонением или средней квадратичной погрешностью отдельного результата.
О тносительное стандартное отклонение или коэффициент вариации (V) вычисляют по соотношению

Дисперсию среднего арифметического вычисляют:

и стандартное отклонение среднего

Следует отметить, что все величины – дисперсия, стандартное отклонение и относительное стандартное отклонение, а так же дисперсия среднего арифметического и стандартное отклонение среднего арифметического – характеризуют воспроизводимость результатов химического анализа.
Используемое при обработке небольших (n<20) выборок из нормально распределенной генеральной совокупности t – распределение (т.е. распределение нормированной случайной величины) характеризуется соотношением

где t p , f – распределение Стьюдента при числе степеней свободы f = n -1 и доверительной вероятности Р=0,95 (или уровня значимости р=0,05) .
Значения t - распределения приведены в таблицах, по ним рассчитывают для выборки в n результатов величину доверительного интервала измеряемой величины для заданной доверительной вероятности по формуле

Доверительный интервал характеризует как воспроизводимость результатов химического анализа, так и – если известно истинное значение х ист – их правильность.
Пример выполнения контрольной работы № 2
Задание
При а нализе воздуха на содержание азота хроматографическим методом для двух серий опытов получены следующие результаты:
Решение :
Проверяем ряды на наличие грубых ошибок по Q-критерию. Для чего их располагаем результаты в ряд по убыванию (от минимума к максимуму или наоборот) :
Первая серия:
77,90<77,92<77,95<77,99<78,05<78,07<78,08<78,10
Проверяем крайние результаты ряда (не содержат ли они грубую ошибку).
Полученное значение сравниваем с табличным (табл.2 приложения). Для n=8, p=0,95 Q таб =0,55.
Т.к. Q таб >Q 1 расчет, левая крайняя цифра не является «промахом».
Проверяем крайнюю правую цифру

Q расч Крайняя
правая цифра так же не является ошибочной. Располагаем
результаты
второго ря
да
в порядке их возрастания: 78,02<78,08<78,13<78,14<78,16<78,20<78,23<78,26. Проверяем
крайние результаты опытов - не являются
ли они ошибочными. Q
(n=8,
p=0,95)=0,55.
Табличное значение. Крайнее
левое значение – не ошибочное. Крайняя
правая цифра (не является ли она
ошибочной). Т.е. 0,125<0,55 Крайнее
правое число не является «промахом». Подвергаем
результаты опытов статистической
обработке. Вычисляем
средневзвешенные результатов: Дисперсия
относительно среднего: Стандартное
отклонение: Стандартное
отклонение среднего арифметического: При
небольших (n<20)
выборках из нормально распределенной
генеральной совокупности следует
использовать t
– распределение, т.е. распределение
Стьюдента при числе степени свободы
f=n-1
и доверительной вероятности p=0,95. Пользуясь
таблицами t
– распределения, определяют для выборки
в n
– результатов величину доверительного
интервала измеряемой величины для
заданной доверительной вероятности.
Этот интервал можно рассчитать: Сравниваем
дисперсии
и
средние результаты
двух
выборочных совокупностей. Сравнение
двух дисперсий проводится при помощи
F-
распределения (распределения Фишера).
Если мы имеем две выборочные совокупности
с дисперсиями S 2 1
и
S 2 2
и
числами степеней свободы f 1 =n 1 -1
и f 2 =n 2 -1,
соответственно, то рассчитываем значение
F: F=S 2 1
/
S 2 2 Причем в
числителе всегда находится большая из
двух
сравниваемых выборочных дисперсий.
Полученный результат сравнивают с
табличным значением. Если F 0
>
F крит
(при р=0,95; n 1 ,
n 2),
то расхождение между дисперсиями значимо
и рассматриваемые выборочные совокупности
различаются по воспроизводимости. Если
расхождение между дисперсиями незначимо,
возможно сравнить средние x 1
и
х 2
двух выборочных совокупностей, т.е.
выяснить, есть ли статистически значимая
разница между результатами анализов.
Для решения поставленной задачи
используют t
– распределение. Предварительно
рассчитывают средневзвешенное двух
дисперсий: И
средневзвешенное стандартное отклонение
а
затем – величину t: Значение
t
эксп
сравнивают с t
крит
при числе степеней свободы f=f 1 +f 2 =(n 1 +n 2 -2)
и выборочной доверительной вероятности
р=0,95. Если при этом t
эксп
>
t
крит
,то
расхождение между средними
Контрольное
задание № 2
Анализ
воздуха на содержание компонента Х
хроматографическим методом для двух
серий дал следующие результаты
(таблица-1). 3.
Принадлежат ли результаты обеих выборок
и одной и той же генеральной совокупности.
Проверить по критерию Стьюдента t (р =
0,95; n
= 8). Таблица-4.2.1-
Исходные данные по контрольному заданию
№ 2 № варианта Ком-понент Математическая статистика
- это раздел математики, изучающий приближенные методы сбора и анализа данных по результатам эксперимента для выявления существующих закономерностей, т.е. отыскания законов распределения случайных величин и их числовых характеристик. В математической статистике принято выделять два основных направления исследований
: 1. Оценка параметров генеральной совокупности. 2. Проверка статистических гипотез (некоторых априорных предположений). Основными понятиями математической статистики являются: генеральная совокупность, выборка, теоретическая функция распределения. Генеральной совокупностью
является набор всех мыслимых статистических данных при наблюдениях случайной величины. Х Г = {х 1 , х 2 , х 3 , …, х N , } = { х i ; i=1,N }
Наблюдаемая случайная величина Х называется признаком или фактором выборки. Генеральная совокупность - есть статистический аналог случайной величины, ее объем N обычно велик, поэтому из нее выбирается часть данных, называемая выборочной совокупностью или просто выборкой. Х В = {х 1 , х 2 , х 3 , …, х n , } = { х i ; i=1,n }
Х В Ì Х Г, n £ N
Выборка
- это совокупность случайно отобранных наблюдений (объектов) из генеральной совокупности для непосредственного изучения. Количество объектов в выборке называется объемом выборки и обозначается n. Обычно выборка составляет 5%-10% от генеральной совокупности. Использование выборки для построения закономерностей, которым подчинена наблюдаемая случайная величина, позволяет избежать ее сплошного (массового) наблюдения, что часто бывает ресурсоемким процессом, а то и просто невозможным. Например, популяция представляет собой множество индивидуумов. Изучение целой популяции трудоемко и дорого, поэтому собирают данные по выборке индивидуумов, которых считают представителями этой популяции, позволяющими сделать вывод относительно этой популяции. Однако, выборка обязательно должна удовлетворять условию репрезентативности
, т.е. давать обоснованное представление о генеральной совокупности. Как сформировать репрезентативную (представительную) выборку? В идеале стремятся получить случайную (рандомизированную) выборку. Для этого составляют список всех индивидуумов в популяции и случайно их отбирают. Но иной раз затраты при составлении списка могут оказаться недопустимыми и тогда берут приемлемую выборку, например, одну клинику, больницу и исследуют всех пациентов в этой клинике с данным заболеванием. Каждый элемент выборки называется вариантой
. Число повторений варианты в выборке называется частотой
встречаемости . Величина называется относительной частотой
варианты, т.е. находится как отношение абсолютной частоты варианты ко всему объему выборки. Последовательность вариант, записанных в возрастающем порядке, называется вариационным рядом
. Рассмотрим три формы вариационного ряда: ранжированный, дискретный и интервальный. Ранжированный ряд
- это перечень отдельных единиц совокупности в порядке возрастания изучаемого признака. Дискретный вариационный ряд
представляет собой таблицу, состоящую из граф, либо строк: конкретного значения признака х i и абсолютной частоты n i (или относительной частоты ω i) проявления i-го значения признака x. Примером вариационного ряда служит таблица Написать распределение относительных частот. Решение
: Найдем относительные частоты. Для этого разделим частоты на объем выборки: Распределение относительных частот имеет вид: Контроль: 0,15 + 0,5 + 0,35 = 1. Дискретный ряд можно изобразить графически. В прямоугольной декартовой системе координат отмечаются точки с координатами () или (), которые соединяются прямыми линиями. Такую ломаную называют полигоном частот.
Построить дискретный вариационный ряд (ДВР) и начертить полигон распределения 45 абитуриентов по числу баллов, полученных ими на приемных экзаменах: 39 41 40 42 41 40 42 44 40 43 42 41 43 39 42 41 42 39 41 37 43 41 38 43 42 41 40 41 38 44 40 39 41 40 42 40 41 42 40 43 38 39 41 41 42. Решение
: Для построения вариационного ряда различные значения признака x (варианты) располагаем в порядке их возрастания и под каждым из этих значений записываем его частоту. Построим полигон этого распределения: Рис. 13.1. Полигон частот Интервальный вариационный ряд
используется при большом числе наблюдений. Для построения такого ряда надо выбрать число интервалов признака и установить длину интервала. При большом числе групп величина интервала будет минимальна. Число групп в вариационном ряду можно найти по формуле Стерджеса : где - максимальное; - минимальное значения вариант, а их разность R носит название размаха вариации
. Исследуется выборка из 100 человек из совокупности всех студентов медицинского ВУЗа. Решение
: Рассчитаем число групп: . Таким образом, для составления интервального ряда данную выборку лучше разбить на 7 или 8 групп. Совокупность групп, на которые разбиваются результаты наблюдений и частот получения результатов наблюдений в каждой группе, называют статистической совокупностью
. Для наглядного представления статистического распределения пользуются гистограммой. Гистограмма частот
- это ступенчатая фигура, состоящая из смежных прямоугольников, построенных на одной прямой, основания которых одинаковы и равны ширине интервала, а высота равна или частоте попадания в интервал или относительной частоте ω i . Наблюдения за числом частиц, попавших в счетчик Гейгера, в течение минуты дали следующие результаты: 21 30 39 31 42 34 36 30 28 30 33 24 31 40 31 33 31 27 31 45 31 34 27 30 48 30 28 30 33 46 43 30 33 28 31 27 31 36 51 34 31 36 34 37 28 30 39 31 42 37. Построить по этим данным интервальный вариационный ряд с равными интервалами (I интервал 20-24; II интервал 24-28 и т.д.) и начертить гистограмму. Решение
: n = 50 Гистограмма этого распределения имеет вид:
Рис. 13.2. Гистограмма распределения Варианты заданий
№ 13.1.
Через каждый час измерялось напряжение тока в электросети. При этом были получены следующие значения (В): 227 219 215 230 232 223 220 222 218 219 222 221 227 226 226 209 211 215 218 220 216 220 220 221 225 224 212 217 219 220. Построить статистическое распределение и начертить полигон. № 13.2.
Наблюдения за сахаром крови у 50 человек дали такие результаты: 3.94 3.84 3.86 4.06 3.67 3.97 3.76 3.61 3.96 4.04 3.82 3.94 3.98 3.57 3.87 4.07 3.99 3.69 3.76 3.71 3.81 3.71 4.16 3.76 4.00 3.46 4.08 3.88 4.01 3.93 3.92 3.89 4.02 4.17 3.72 4.09 3.78 4.02 3.73 3.52 3.91 3.62 4.18 4.26 4.03 4.14 3.72 4.33 3.82 4.03 Построить по этим данным интервальный вариационный ряд с равными интервалами (I - 3.45-3.55; II - 3.55-3.65 и т. д.) и изобразить его графически, начертить гистограмму. № 13.3.
Построить полигон частот распределения скорости оседания эритроцитов (СОЭ) у 100 человек. Математическая статистика – это раздел математики, которая изучает методы собирания, систематизации и обработки результатов наблюдений массовых случайных событий с целью выяснения и практического применения существующих закономерностей. Методы математической статистики нашли широкое применение в клинической медицине и здравоохранении. Они используются, в частности, при разработке математических методов медицинской диагностики, в теории эпидемий, в планировании и обработке результатов медицинского эксперимента, в организации здравоохранения. Статистические концепции, сознательно или бессознательно, используются при принятии решений в таких вопросах, как клинический диагноз, прогнозирование течения болезни у отдельного больного, прогнозирование возможных результатов осуществления тех или других программ в данной группе населения и выбор надлежащей программы в конкретных обстоятельствах. Знакомство с идеями и методами математической статистики является необходимым элементом профессионального образования каждого работника здравоохранения.
Применение статистики в здравоохранении необходимо как на уровне сообщества, так и на уровне отдельных пациентов. Медицина имеет дело с индивидуумами, которые отличаются друг от друга по многим характеристикам, и значение показателей, на основе которых человека можно считать здоровой, варьируются от одного индивидуума к другому. Нет двух абсолютно одинаковых пациентов или двух групп пациентов, поэтому решение, которые касаются отдельных больных или групп населень, приходится принимать, исходя из опыта, накопленного на других больных или популяціних группах с похожими биологическими характеристиками. Необходимо осознавать, что учитывая существующие расхождения эти решения не могут быть абсолютно точными - они всегда связаны с некоторой неопределенностью. Именно в этом состоит
ймовірносна природа медицины.
Задача выборочного метода заключается в том, чтобы по полученной избирателю сделать правильную оценку случайной величины, которая изучается. Поэтому основное требование, которое пред"яв-ляється к виборки, это максимальное отображение всех черт генеральной совокупности. Виборка, что удовлетворяет этому требованию, называется
репрезентативной.
От репрезентативности виборки зависит
обгрунтованість
оценки, то есть степень соответствия оценки параметру, который она характеризует
.
Выводы, которые получаются методами математической статистики, всегда основываются на ограниченном, выборочном числе наблюдений, поэтому природньо, что для второй виборки результаты могут быть другими. Это обстоятельство определяет
ймовірносний характер выводов математической статистики
и, как следствие, широкое использование теории вероятностей в практике статистического исследования.
уменьшается с ростомn, итак, при постоянной величине надежного интервала с ростомn растет и . При постоянной надежной вероятности с ростом объема виборкип уменьшается величина надежного интервала. При планировании медицинских исследований эта связь используют для определения минимального объема виборки, который обеспечит нужны по условиям решаемой задачи величины надежного интервала и надежной вероятности.


 -
для первого ряда результатов.
-
для первого ряда результатов. -
для второго ряда результатов.
-
для второго ряда результатов. -
для первого ряда.
-
для первого ряда. -
для второго ряда.
-
для второго ряда. -
для первого ряда.
-
для первого ряда. -
для второго ряда.
-
для второго ряда.





 и
и
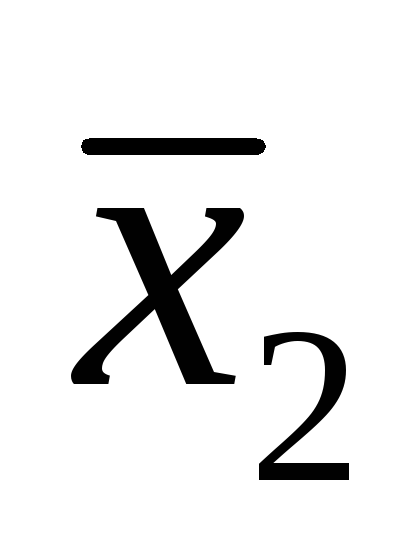 значимо и выборка не принадлежит одной
и той же генеральной совокупности. Если
t эксп <
t крит,
расхождение между средними незначимо,
т.е. выборки принадлежат одной и той же
генеральной совокупности, и, следовательно,
данные обеих серий можно объединить и
рассматривать их как одну выборочную
совокупность из n 1 +n 2
результатов.
значимо и выборка не принадлежит одной
и той же генеральной совокупности. Если
t эксп <
t крит,
расхождение между средними незначимо,
т.е. выборки принадлежат одной и той же
генеральной совокупности, и, следовательно,
данные обеих серий можно объединить и
рассматривать их как одну выборочную
совокупность из n 1 +n 2
результатов.
0,15
0,5
0,35

![]() (k-число групп, n - объем выборки), а ширину интервала -
(k-число групп, n - объем выборки), а ширину интервала - ![]()

1.Тема: “ Основы математической статистики”.
2. Актуальность темы.
Студент должен
знать
(2 уровень):
Студент должен овладеть элементарными привычками вычисления (3 уровень):
4. Пути реализации целей занятия:
Для реализации целей занятия Вам необходимые такие исходные знания:
Вам необходимые также уметь вычислять вероятностей несовместимых и совместных событий с помощью соответствующих правил.
5. Задача для проверки студентами своего исходного уровня знаний
.
Контрольные вопросы
6. Информацию для упрочения исходных знаний-умений можно найти в пособиях:
7. Содержание учебного материала из данной темы с выделением основных узловых вопросов.
Математическая статистика -
это раздел математики, которая изучает методы сбора, систематизации, обработки, изображение, анализа и интерпретации результатов наблюдений с целью выявления существующих закономерностей.
Некоторые примеры применения статистических методов в медицине:
трактовка вариации
(вариабельность характеристик организма при решении вопроса о том, какое значение той или другой характеристики будет идеальным, нормальным, средним и т.і., делает необходимым использование соответствующих статистических методов).
диагностика заболеваний
в отдельных больных и оценка состояния здоровья группы населения.
прогнозирование конца болезни
в отдельных больных или возможного результата программы борьбы по той или другой болезнью в любой группе населения.
выбор пригодного влияния
на больного или на группу населения
.
планирование и проведение медицинских исследований
, анализ и публикація результатов, их чтение и критическая оценка.
планирование здравоохранения
и руководство им
.
Полезная медицинская информация обычно скрыта в массе необработанных данных. Необходимо сконцентрировать информацию, которая содержится в них, и представить данные так, чтобы структуру вариации было хорошо видно, а потом уже выбрать конкретные методы анализа.
Изображение данных
предусматривает знакомство с такими понятиями и сроками:
вариационный ряд
(упорядоченное расположение) - простое упорядочение отдельных наблюдений за величиной.
класс -
один из интервалов, на которые делят весь диапазон значений случайной величины.
крайние точки класса -
значение, которые ограничивают класс, например 2,5 и 3,0, нижняя и верхняя границы класса 2,5 - 3,0.
(абсолютная) частота класса -
число наблюдений в классе.
относительная частота класса -
абсолютная частота класса, выраженная в виде частные общего числа наблюдений.
кумулятивная (накопленная) частота класса -
число наблюдений, которое равняется сумме частот всех предыдущих классов и данного класса
.
стовпцева диаграмма -
графическое изображение частот данных для номинальных классов с помощью столбцов, высоты которых прямо пропорциональные частотам классов.
круговая диаграмма -
графическое изображение частот данных для номинальных классов с помощью секторов круга, площади которых прямо пропорциональные частотам классов.
гістограма -
графическое изображение частотного распределения количественных данных площадями прямоугольников, прямо пропорциональных частотам классов.
полигон частот -
график частотного распределения количественных данных; точку, соответствующую частоте класса, располагают над серединой интервала, каждое две соседние точки соединяют отрезком прямой.
огива (кумулятивная кривая) -
график распределения кумулятивных относительных частот.
Всем медицинским данным присущий вариабельность, тому анализ результатов измерений основанный на изучении сведений о том, каких значениях принимала случайная величина, которая исследуется.
Совокупность всех возможных значений случайной величины называется
генеральной.
Часть генеральной совокупности, зарегистрированная в результате испытаний, носит название
виборкою.
Число наблюдений, включенное в виборку, зовут
объемом виборки
(обычно обозначается
n
)
.
При оценивании параметров генеральной совокупности по избирателю
(параметрическом оценивании) пользуются
такими понятиями:
точечное оценивание -
оценка параметра генеральной совокупности в виде единичного значения, которое он может принять с самой большой вероятностью.
интервальне оценивание -
оценка параметра генеральной совокупности в виде интервала значений, который имеет заданную вероятность накрыть его истинное значение.
При інтервальному оценивании используют понятие:
надежный интервал -
интервал значений, который имеет заданную вероятность накрыть истинное значение параметра генеральной совокупности при інтервальному оценивании.
достоверность (надежная вероятность) -
вероятность, с которой надежный интервал накрывает истинное значение параметра генеральной совокупности.
надежные границы -
нижняя и верхняя границы надежного интервала.
Типичный путь статистического исследования
такой
:
оценивши величины или зависимости между ними по данным наблюдений, выдвигают допущение о том, что явление, которое изучается, можно описать той или другой стохастичною моделью
используя статистические методы, можно это предположение подтвердить или отвергнуть; при подтверждении цель достигнута - найдена модель, которая описывает исследуемые закономерности, в противоположном случае продолжают работу, выдвигая и проверяя новую гипотезу.
Определение выборочных статистических оценок:
мода -
это значения, которое чаще всего встречается в избирателе
,
медиана -
центральное (срединное) значение вариационного ряда
размах R -
разность между самым большим и наименьшим значениями в серии наблюдений
процентилі -
значение в вариационном ряде, которые делят распределение на 100 равных частей (таким образом, медиана будет п"ятидесятим процентилем)
первый квартиль - 25-
ий процентиль
третий квартиль - 75-
ий процентиль
міжквартильний размах -
разность между первым и третьим квартилями (охватывает центральных 50% наблюдений)
квартильне отклонение -
половина міжквартильного размаха
выборочное среднее -
среднее арифметическое всех выборочных значений (выборочная оценка математического ожидания)
среднее абсолютное отклонение -
сумма отклонений от соответствующего начала (без учета знака), разделенная на объем виборки
среднее абсолютное отклонение от выборочного среднего
вычисляют за формулой
выборочная дисперсия
(
X
)
-
(выборочная оценка дисперсии) определяется формулой
выборочная коваріація --
(выборочная оценка коваріації
К
(
Х,Y
)) равняется
выборочный коэффициент регрессии Y на X
(выборочная оценка коэффициента регрессии
Y
на
X
) равняется
эмпирическое уравнение линейной регрессии Y на X
имеет вид
выборочный коэффициент регрессии X на Y
(выборочная оценка коэффициента регрессии X на Y) равняется
эмпирическое уравнение линейной регрессии X на Y
имеет вид
выборочное стандартное отклонение s(Х) -
(выборочная оценка стандартного отклонения) равняется корню квадратному из выборочной дисперсии
выборочный корреляційний коэффициент -
(выборочная оценка корреляционного коэффициента) равняется
выборочный коэффициент вариации
-
(выборочная оценка коэффициента вариации CV) равняется
.
8. Задача для самостоятельной подготовки студентов
.
8.1 Задача для самостоятельного изучения материала с темы.
8.1.1 Практическое вычисление выборочных оценок
Практическое вычисление выборочных точечных оценок
Пример 1
.
Продолжительность заболевания (в днях) в 20 случаях пневмонии сложила:
10, 11, 6, 16, 7, 13, 15, 8, 9, 10, 11, 13, 7, 8, 13, 15, 16, 13, 14, 15
Определить моду, медиану, размах, міжквартильний размах, выборочное среднее, среднее абсолютное отклонение от выборочного среднего, выборочную дисперсию, выборочный коэффициент вариации.
Розв"зок.
Вариационный ряд для виборки имеет вид
6, 7, 7, 8, 8, 9, 10, 10, 11, 11, 13, 13, 13, 13, 14, 15, 15, 15, 16, 16
Мода
Наиболее часто в избирателе встречается число 13. Поэтому значением моды в избирателе будет это число.
Медиана
Когда вариационный ряд содержит парное число наблюдений, медиана равняется среднему двух центральных членов ряда, в данном случае это 11 и 13, поэтому медиана равняется 12.
Размах
Минимальное значение в избирателе равняется 6, а максимальное 16, итак,
R
= 10.
Міжквартильний размах, квартильне отклонение
В вариационном ряде четверть всех данных имеет значение меньшие, или уровне 8, поэтому первый квартиль 8, а 75% всех данных имеют значение меньшие, или уровне 12, поэтому третий квартиль 14. Итак, міжквартильний размах равняется 6, а квартильне отклонение составляет 3.
Выборочное среднее
Среднее арифметическое всех выборочных значений равняется
.
Среднее абсолютное отклонение от выборочного среднего
.
Выборочная дисперсия
Выборочное стандартное отклонение
.
Bибірковий коэффициент вариации
.
В следующем примере рассмотрим простейшие средства изучения стохастичної зависимости между двумя случайными величинами.
Пример 2
.
При обследовании группы пациентов получены данные о росте
Н
(см) и объем циркулирующей крови
V
(л) :
Найти эмпирические уравнения линейной регрессії.
Розв"зок.
Первое, что необходимо вычислить, это:
выборочное среднее
выборочное среднее
.
Второе, что необходимо подсчитать, это:
выборочную дисперсию (Н)
выборочную дисперсию (V)
выборочную коваріацію
Третье, это вычисления выборочных коэффициентов регрессии:
выборочный коэффициент регрессии
V
на
H
выборочный коэффициент регрессии
H
на
V
.
Четвертое, записать искомые уравнения:
эмпирическое уравнение линейной регрессии
V
на
H
имеет вид
эмпирическое уравнение линейной регрессии
H
на
V
имеет вид
.
Пример 3
.
Используя условия и результаты примера 2, высчитать коэффициент корреляции и проверить достоверность существования корреляционной зависимости между ростом человека и объемом циркулирующей крови с 95% надежной вероятностью.
Розв"зок.
Коэффициент корреляції связан с коэффициентами регрессии
и практически полезной формулой
.
Для выборочной оценки коэффициента корреляції эта формула имеет вид
.
Используя вираховані в примере 2 значение выборочных коэффициентов регрессії и, получим
.
Проверка достоверности корреляційної зависимости между случайными величинами (полагает нормальное распределение у каждой из них) осуществляется таким образом:
.
Поскольку 3,5 > 2,26, то с 95% надежной вероятностью существования корреляционной зависимости между ростом пациента и объемом циркулирующей крови можно считать установленным.
Інтервальні оценки для математического ожидания и дисперсии
Если случайная величина имеет нормальное распределение, то інтервальні оценки для математического ожидания и дисперсии вычисляют в такой последовательности:
1.находят выборочное среднее;
2.подсчитывают выборочную дисперсию и выборочное стандартное отклонение
s
;
3.в таблице распределения Стьюдента за надежной вероятностью
и объемом виборки
n
находят коэффициент Стьюдента;
4.надежный интервал для математического ожидания записывают в виде
5.в таблице распределения "> и объемом виборкиn находят коэффициенты
;
6.надежный интервал для дисперсии записывают в виде
Величина надежного интервала, надежная вероятность и объем виборкиn зависят друг от друга. На самом деле, отношение
Пример 5.
Используя условия и результаты примера 1, найдите інтервальні оценки математического ожидания и дисперсии для 95% надежной вероятности.
Розв"зок.
В примере 1 вираховані точечные оценки математического ожидания (выборочное среднее =12), дисперсии (выборочная дисперсия =10,7) и стандартного отклонения (выборочное стандартное отклонение). Объем виборки равняетсяп = 20.
Из таблицы распределения Стьюдента найдем значение коэффициента
дальше вычислим полуширинуd надежного интервала
и запишем інтервальну оценку математического ожидания
10,5 < < 13,5 при = 95%
Из таблицы распределения Пірсона " хи-квадрат " найдем коэффициенты
вычислим нижнюю и верхнюю надежные границы
и запишем інтервальну оценку для дисперсии в виде
6,2 23 при = 95% .
8.1.2. Задачи для самостоятельного решения
Для самостоятельногорешения предлагаются задачи5.4 С 1 – 8 (П.Г.Жуматій. “Математическая обработка медико-биологических данных. Задачи и примеры”. Одесса, 2009, с. 24-25)
8.1.3. Контрольные вопросы
8.2 Основная литература
8.3 Дополнительная литература
Методические указания сложилдоц. П. Г. Жуматій.